|
A biblioteca de Babel Introdução
Jorge Luis Borges, em seu conto "A Biblioteca de Babel", descreve um espaço tão grande que não pode ser percorrido e onde toda informação do mundo (e a desinformação também) estão à disposição de todos, inclusive a história passada e futura de suas vidas e todas as suas diferentes vidas possíveis ou não. A coleção desta biblioteca é tão vasta e avassaladora que encontrar algo de valor nela é quase impossível. Diferente de uma biblioteca, entretanto, a esmagadora maioria dos documentos colocados na Internet não obedecem a nenhuma classificação sistemática, como o código de Dewey, onde as obras são catalogadas por assunto, por exemplo. A disponibilização de documentos é feita, em geral, por pessoa que não são profissionais da área de informação e documentação. Por esta razão, encontrar informação e garantir sua validade não é fácil.
Existem iniciativas, como o "Dublin Core", que representam uma primeira tentativa de organização do caos mas, atualmente, a pesquisa na Internet pode ser feita apenas por dois recursos: a navegação aleatória ou através do uso dos sites de catalogação e indexação.
Sumários versus Indexes
Semelhante aos livros, existem 2 estratégias de buscar informação de modo sistemático:
2. Os sites indexadores, search-engines, cujos robots ou crawlers percorrem incessantemente todos os sites e atualizam a meta informação a respeito do conteúdo dos mesmos, para um search-engine específico, que salva os dados em ordem alfabética, exatamente como num livro.
A resposta é mais uma questão de bom-senso. Páginas realmente importante são indexadas manualmente (valem o esforço de descrevê-las e detalhá-las uma a uma, para o formulário de submisão do site catalagador) mas elas existem em menor número. Para uma "varredura" completa, sites indexadores levantam
Operadores lógicos
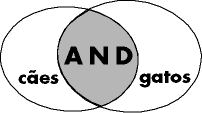
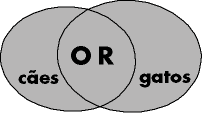
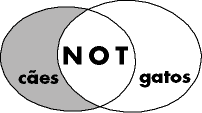
A lógica booleana (inventada por Boole), consiste em construir afirmações lógicas utilizando os chamados "operadores lógicos", que aproximam ou separam os elementos, possibilitando refinar a busca e recuperar dados pertinentes. 1. NEAR - Altavista e OpenText são search-engines que, neste momento, utilizam este operador de proximidade. Isto quer dizer que ambos os termos definidos devem estar próximos um do outro, geralmente na mesma frase. Isto permite refinar a busca de forma muito eficiente. Diferente do AND, que requer apenas a presença de ambos os termos em qualquer lugar do documento, o NEAR cria um link conceitual entre ambos. 2. FOLLOWED BY - Atualmente apenas o OpenText oferece este operador que liga dois termos ou frases de modo que um preceda o outro na ordem determinada. Em muitos search-engines isto equivale a usar ambos os termos entre aspas. Ex. Porto FOLLOWED BY Alegre. Ou "Porto Alegre". É possível colocar diversas palavras entre aspas ou mesmo uma frase inteira: "Festival de Cinema de Gramado". Outros usam o "_", como em: Porto_Alegre. 2. ADJ (adjacent) - Utilizados para termos juntos e na mesma ordem. Dog ADJ cat produz resultados diferentes de cat ADJ dog.
4. Os bons search-engines permitem também que se use wildcards* ou palavras truncadas, para abranger o maior número de variações em torno de um radical. Por exemplo, caminh* abrangerá resultados com "caminho", "caminhada", "caminhão", etc. Em geral são buscados até 3 caracteres após o asterisco.
Altavista (www.altavista.com) Desenvolvido pela Digital Corp. é um dos mais poderosos e flexíveis search-engines globais, atualmente. Os indexes são atualizados diariamente, a freqüência e a proximidade de palavras significativas são registradas, e formam a base da ordem do display do resultado da busca. Em 97 já possuía 31 milhões de registros para webpages, de 620.000 servidores por todo o mundo. Indexa também os 4 milhões de artigos postados pelos grupos da Usenet diariamente. Seu site é acessado 30 milhões de vezes a cada dia. Seu search-engine permite a utilização de operadores lógicos e de proximidade, bem como o uso de termos truncados.
Desenvolvido pela Excite Inc., usa um web crawler e oferece reviews de sites em uma grande variedade de categorias. Excite! se autoproclama como sendo a melhor ferramenta de busca na www com mais de 50 milhões de sites indexados em 1997. Este search-engine utiliza uma tecnologia de Inteligência Artificial "ICE" (Inteligent Concept Extraction) para estabelecer relações entre os termos das páginas indexadas. O search-engine lida também com frases coloquiais e utiliza fuzzy logic para encontrar resultados relevantes. Por isto o Excite! é muito útil para os novos usuários utilizarem, porque procura compensar as buscas mal-formuladas e monta listas por relevância.
Desenvolvido por Inktomi Corp. recentemente, o hotbot é o search-engine da revista WIRED e afirma possuir o maior e mais completo index de documentos da www, utilizando elementos de inteligência artificial para recuperar informações através de uma grande variedade de opções, acessíveis através do search control panel.
Desenvolvido pela Infoseek Corp., este search-engine foi criado em 1994 e, naturalmente, proclama possuir o mais vasto diretório de sites organizado. Sua atuação o coloca sempre no topo da lista de performance de indexadores, anualmente. Usuários de Windows podem adicionar a capacidade de busca do Infoseek na barra do menu, fazendo o download do software sugerido no site.
(Para uma lista mais completa de search engines, consulte:
Cada documento HTML (a linguagem de marcação de páginas que permite aos browsers como Netscape, Explorer, Lynx, etc. visualizar a informação) colocado no WWW possue duas partes em sua estrutura: o <HEAD>, a parte "invisível" do documento e o <BODY>, a parte que contém o que será mostrado na tela do usuário. A maioria das pessoas não utiliza o <HEAD> para garantir uma recuperação inteligente de seus documentos. Por exemplo, o leigos não costumam preencher o campo <TITLE>, razão pela qual tantos documentos aparecem como "Untitled" quando se faz uma busca num search-engine como o Alta-Vista. É a marcação (ou tag - etiqueta) <TITLE> também que cria o nome da bookmark ou favoritos e, igualmente importante, é o conteúdo do campo <TITLE> que dá a maior pontuação quando os mecanismos de busca precisam criar uma lista hierárquica dos documentos recuperados para determinadas palavras chaves. Outros tags importantes são a família dos <META NAME>: description, keywords e author. Em <META NAME="description" CONTENT="manual de treinamento de cães de companhia">, por exemplo, o campo "CONTENT" descreve o conteúdo do documento. O tag <META NAME="keywords" CONTENT="treinamento, cão, cães, caninos, manual, companhia, adestramento, hábitos"> é campo o onde podem ser colocadas as palavras-chave ). Não vale colocar Tiazinha, ou Cindy Crawford!!! ainda que muitas pessoas mal-intencionadas façam isto para aumentar a recuperação e a estatística de acesso. Finalmente o tag <META NAME="author" CONTENT="Analú da Silva"> é o campo onde o autor pode garantir que, se for feita uma busca de seu portofólio virtual, seus documentos serão recuperados mesmo que seu nome não conste do corpo do documento, como no caso de uma página institucional.
Colocar palavras chaves através dos meta tags, assim como preencher o campo <TITLE> auxilia os search engines a avaliar a importância e a pertinência daquele documento na lista indexada que é criada para cada busca. E pode significar a diferença entre ser visto ou não pelo mundo.
Marilia Levacov

|